
[樂遊網導讀]ai孫燕姿什麼意思?一夜之間“AI孫燕姿”火遍全網,由此引發了大家對ai音頻轉換工具的相關探討,ai孫燕姿是使用GitHub上麵的一個開源項目SO-VITS-SVC製作而來,用戶可以在此項目中通過ai智能工具收集孫燕姿的音色,從而生成目標音色模型來翻唱作品,ai孫燕姿怎麼做的?不知道的朋友趕緊來看看!
ai孫燕姿什麼意思?一夜之間“AI孫燕姿”火遍全網,由此引發了大家對ai音頻轉換工具的相關探討,ai孫燕姿是使用GitHub上麵的一個開源項目SO-VITS-SVC製作而來,用戶可以在此項目中通過ai智能工具收集孫燕姿的音色,從而生成目標音色模型來翻唱作品,ai孫燕姿怎麼做的?不知道的朋友趕緊來看看!

ai孫燕姿什麼意思
一夜之間“AI孫燕姿”火遍全網。在B站上,AI孫燕姿翻唱的林俊傑《她說》、周董《愛在西元前》、趙雷《成都》等等,讓一眾網友深陷無法自拔。網友表示,聽了一晚上AI孫燕姿,出不去了......
這些翻唱作品基於一個叫做so-vits-svc的開源項目。僅憑數段音頻,就可用一個生成式模型來合成目標音色的音頻,訓練出用戶想要的聲學模型。這個模型可以保留音高和音調,也可以用不同的語言來翻唱。
ai孫燕姿下載:【點擊下載】
ai孫燕姿怎麼做的
方法一:
一、準備工作
訓練數據很關鍵,越多高質量的音頻數據,效果越好,建議至少準備一個小時以上的音頻。
顯卡建議使用 N 卡且顯存 8G 以上。
我將項目所需要的代碼、工具整理了出來,如有需要可以在評論區留言或者通過下方鏈接聯係我。
當然,也可以直接用開源代碼直接部署,地址如下
GitHub - svc-develop-team/so-vits-svc: SoftVC VITS Singing Voice Conversion
二、環境安裝
1.安裝pytorch深度學習框架
需要安裝pytorch,torchaudio,torchvision三個庫
參考我之前寫的https://yunlord.blog.csdn.net/article/details/129812705?spm=1001.2014.3001.5502
2.安裝相關依賴
可以看到下載的項目中包含兩個requirements.txt,以windows為例,
進入到項目中,通過prompt輸入以下指令,
pip install -r requirements_win.txt
三、數據處理
訓練音頻、還有需要預測,或者說轉換的音頻都必須是人物的幹聲。換句話說音頻中不能包含背景音、伴奏、合聲等,所以無論是訓練和預測,都需要對數據進行處理。
1.提取人聲
我們可以通過UVR5 這個軟件實現伴奏與人聲分離。
在 Windows 下可以直接使用。打開軟件,按照如下配置

運行即可分離人聲和伴奏。
然後再按照如下配置,去除合聲,
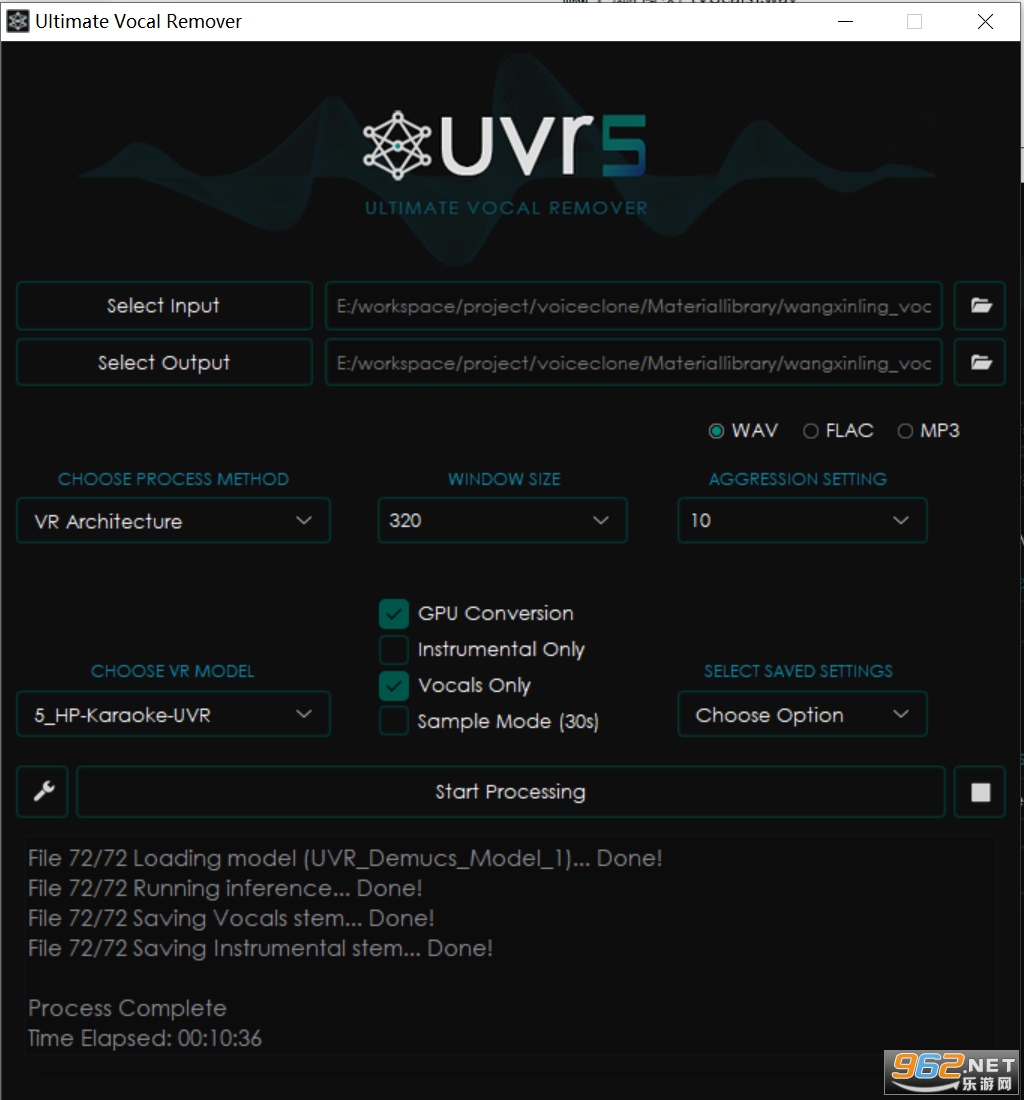
經過提取出的幹淨人聲音頻就可以用來訓練。
2.切割音頻
不過因為音頻太長,不要超過三十秒,很容易爆顯存,需要對音頻文件進行切片。
我們通過 Audio Slicer這個工具實現音頻切分 。
直接運行 slicer-gui.exe。
填寫輸入路徑,填寫輸出路徑,其它參數都默認即可,這樣就會得到切分好的音頻段。

建議切完之後逐段聽下,將效果不好的刪除,高質量的音頻比數量多的效果更好。並且如果還有時長超過30s的可以通過寫的python音頻切割代碼進行截切。
在項目的 so-vits-svc-4.0/dataset_raw 目錄下創建一個文件夾,比如我的是 wang_processed,將處理好的數據放到裏麵。
四、訓練模型
在訓練模型前,我們需要下好原始模型,並將其放到對應位置
將checkpoint_best_legacy_500.pt放入hubert文件夾下
將D_0.pth和G_0.pth放入logs/44k目錄下
1.數據預處理
接下來可以直接運行項目裏麵的1.數據預處理.bat。
這個腳本就是按照步驟,運行各個 py 腳本
重采樣至44100Hz單聲道
python resample.py
自動劃分訓練集、驗證集及自動生成配置文件
python preprocess_flist_config.py
生成hubert與f0
python preprocess_hubert_f0.py
處理完畢後會在 datset/44k 下生成一個文件夾。裏麵的數據如下圖所示
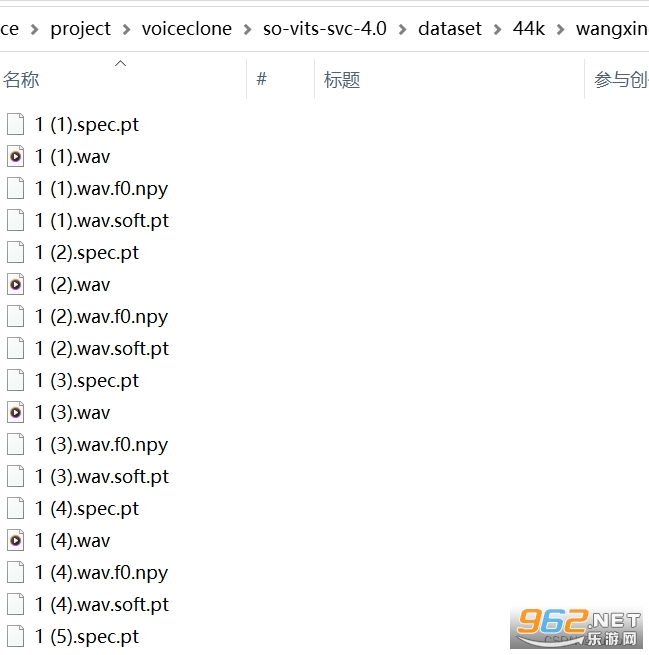
可以刪除 dataset_raw 文件夾了。
2.模型訓練
直接運行項目中的2.訓練.bat即可開啟訓練。
python train.py -c configs/config.json -m 44k
如果顯卡夠好可以增加 batch_size 提高訓練速度對應的配置文件在 configs/config.json 文件裏。
這個訓練時間很長,個人覺得如果數據較好的話,訓練到30000輪以上就有一個不錯的效果。
3.聚類模型訓練
直接運行項目中的3.訓練聚類模型.bat即可開啟訓練,這個比較快,幾分鍾即可跑完。
這個主要是可以減小音色泄漏,使得模型訓練出來更像目標的音色,但其實不是特別明顯,但是單純的聚類方案會降低模型的咬字,會口齒不清,這個很明顯,本模型采用了融合的方式,可以線性控製聚類方案與非聚類方案的占比,也就是可以手動在像目標音色和咬字清晰之間調整比例,找到合適的折中點。
使用聚類前麵的已有步驟不用進行任何的變動,隻需要額外訓練一個聚類模型,雖然效果比較有限,但訓練成本也比較低。
訓練過程,
執行python cluster/train_cluster.py,模型的輸出會在logs/44k/kmeans_10000.pt
推理過程,
inference_main.py中指定cluster_model_path
inference_main.py中指定cluster_infer_ratio,0為完全不使用聚類,1為隻使用聚類,通常設置0.5即可
4.推理預測
準備幹聲
準備一首歌的幹聲,幹聲可以按上述音頻素材準備那樣處理,通過UVR5提取一段不超過90s的幹聲素材。
修改模型名
修改 app.py 裏的這一行
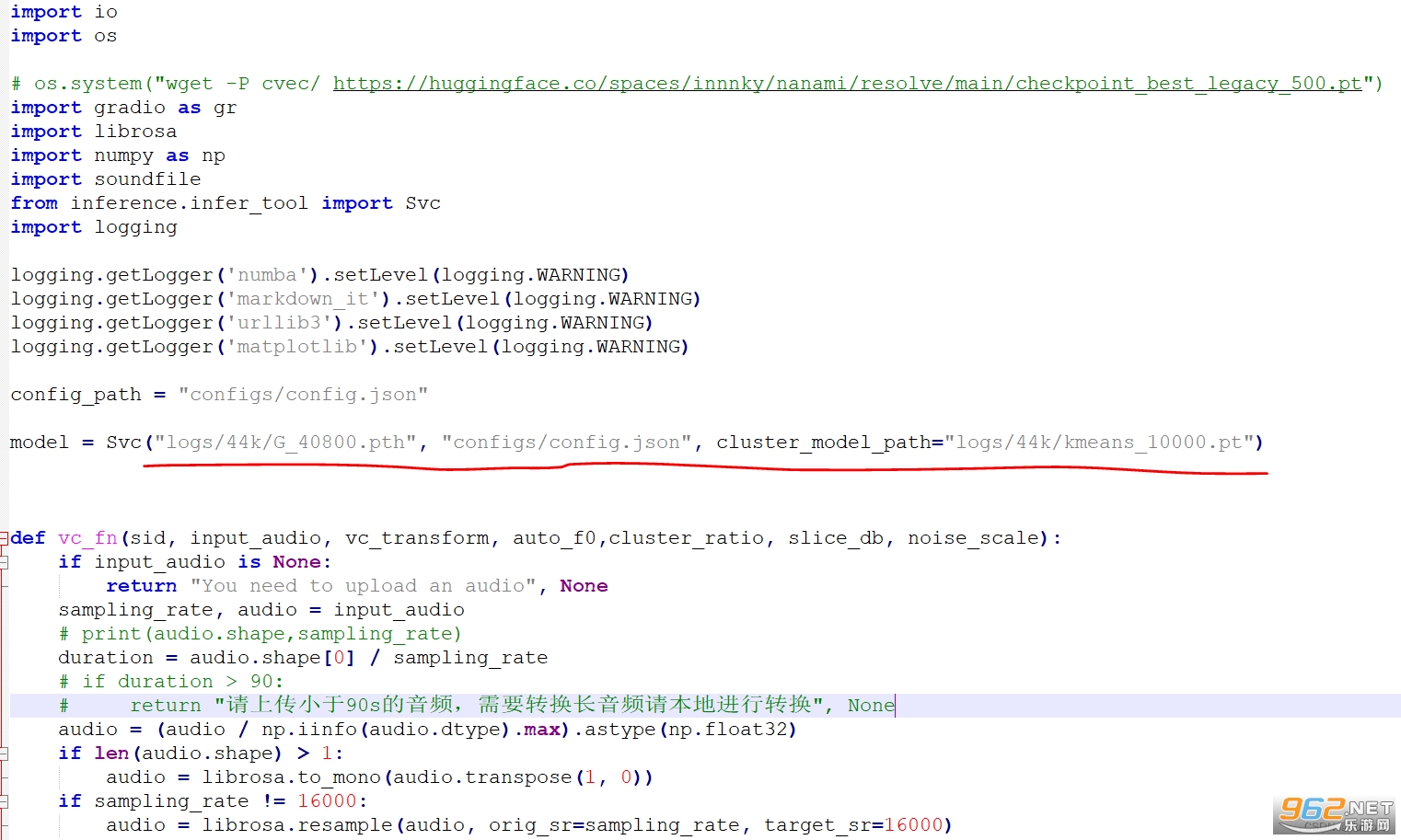
訓練好的模型存放在了 logs/44k 目錄下這裏改為訓練好的模型地址。以及對應的配置文件,最後是第三步生成的 pt 文件路徑。
運行web
直接運行項目中的4.推理預測.bat。
程序會直接開啟一個 webui,將開啟的 url,直接複製到瀏覽器地址欄中打開即可。
就是一個簡單的 Web 頁麵,裏麵的參數,可以直接使用默認的,放入一個音頻,即可轉換音色。
方法二:
下載GitHub app,按照如下教程進行操作
GitHub下載:【點擊下載】
github可以很方便地讓我們參與開源項目中,並貢獻自己的代碼.那麼,我們怎麼去參與一個開源的github項目呢?
首先,去訪問你要參與的github主頁,點擊“Fork” => create Fork.

2. 然後,這樣就把這份項目拷貝到了你的遠程倉庫,用你自己的賬號登錄查看你的倉庫,會發現你的倉庫已經有了這個項目,點擊Code,copy你的github地址,一定要注意,要在自己的github賬號上進行,不要在項目作者的倉庫上,因為你木有權限,你是不能進行推送和修改的.


3.如圖,在git裏利用命令git clone + copy的github地址把倉庫克隆到你的工作區上,
clone完成後你就可以在你的工作區看到這個項目文件,然後你就可以開始幹活了,
幹完活後,先把你的代碼提交到你的倉庫中裏:
git add test.md;
gti commit -m something
git push origin,遠程倉庫, -u master,本地分支,
注push 加上 -u 參數 是為了讓你的遠程倉庫與你的本地分支建立連接,以後push的時候就可以不必加上這個參數了.
然後在你的賬號下進行 Pull requests貢獻你的代碼了
至於對方是否接受你的代碼,要看對方的心情了

 喜歡
喜歡  頂
頂  無聊
無聊  圍觀
圍觀  囧
囧  難過
難過


 airasia(com.airasia.mobile)app v11.48.0
安卓旅行交通 / 23-05-11
airasia(com.airasia.mobile)app v11.48.0
安卓旅行交通 / 23-05-11
 優巡ai雲監考v1.3.0 官方版
安卓實用工具 / 23-05-11
優巡ai雲監考v1.3.0 官方版
安卓實用工具 / 23-05-11
 gencraft ai繪畫 v1.1.1
安卓實用工具 / 23-05-08
gencraft ai繪畫 v1.1.1
安卓實用工具 / 23-05-08
 電動火車模擬器Electric Trains0.767版本v0.767 最新版
安卓休閑益智 / 23-05-05
電動火車模擬器Electric Trains0.767版本v0.767 最新版
安卓休閑益智 / 23-05-05
 project sekai台服安卓 v2.0.0
安卓音樂舞蹈 / 23-05-04
project sekai台服安卓 v2.0.0
安卓音樂舞蹈 / 23-05-04
熱門評論
最新評論